这几天,国内发布了最强 AI 音乐模型:Mureka V7。 它不只可以作曲、配器、翻唱周杰伦,甚至可以用你的声音做专辑。
一句话:把音乐创作变成“打字游戏”。我亲测了一整天,感受就是太牛了,结果让我直呼——Suno 都要小心了。
这次发布的最新版本的 Mureka V7 大模型,大幅改善了动机与旋律质量,可以制作质感更为细腻的个人独家 BGM,简单讲就是人声和旋律动机质量极大提升。
同时,新上线 Voice Design 功能,用户可以使用自定义文本控制音色生成。
有一说一,只要底层技术跟得上,要论做产品,硅谷的公司都无法与我们国内的公司相媲美。
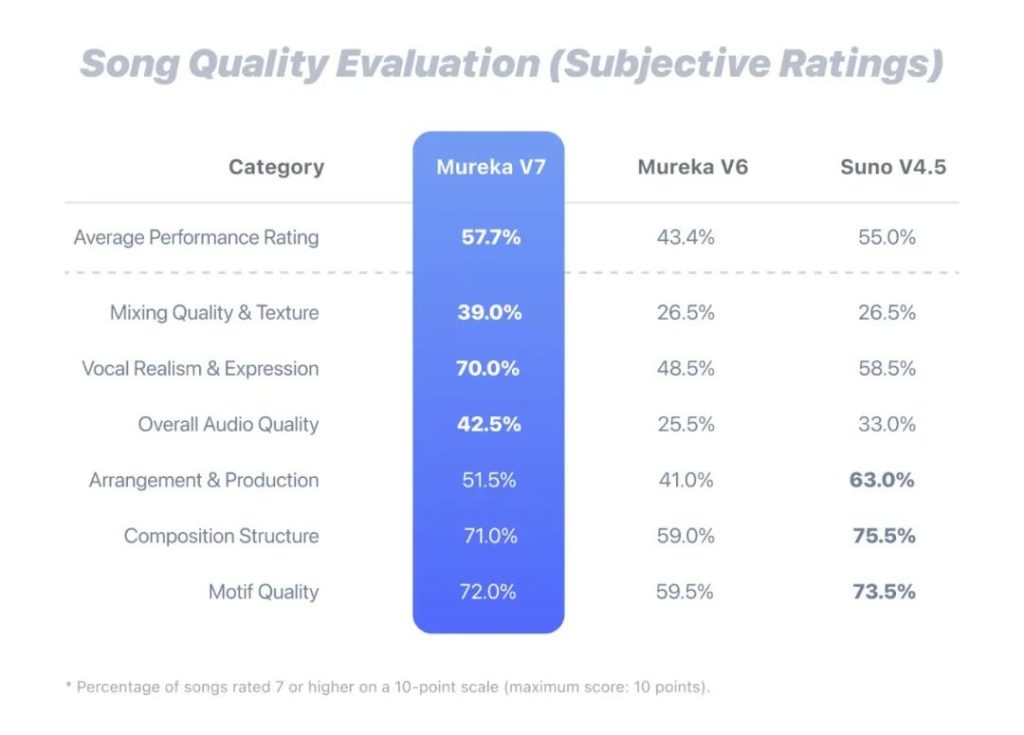
通过我的实测体验,Mureka V7 可以说在底层这种大模型的技术上,生成音乐的能力,不亚于国外的 Suno AI 音乐平台,甚至多项指标超越 Suno。堪称目前国产自研的最强 AI 音乐大模型。
如果你不知道 Mureka ,肯定知道昆仑万维,国内最早打造 AI 音乐大模型的公司。
没错,Mureka 就是昆仑万维打造的 AI 音乐平台,Mureka 是全球首个开放 API 服务以及模型微调功能的 AI 音乐生成平台,不论是开发者,还是音乐平台,现在都可以将 Mureka 的音乐生成能力无缝集成到自己的产品或平台中,更容易地应用AI音乐功能拓展自己的商业价值;而对于普通用户,可以通过网页和 App 随时随地创作无门槛的创作音乐内容。
这就是为什么我说只要底层技术跟得上,硅谷的公司都无法与我们国内的公司相媲美,因为我们国内的公司在做产品的人性化体验和功能的丰富度角度来讲,真的是太贴心了,Mureka 这次 V7 版本的发布,不仅技术能力强大了,功能也越来越贴心和人性化了。
所以,经过的体验之后,给我一个很大的感受就是 Mureka,它不仅仅是一个简单的音乐生成工具,而是一个完整的音乐创作生态系统。
听我具体聊一聊我的使用感受。
音乐模型
从技术的角度来讲,最新上线的 Mureka V7 版本在人声与配器音质方面相比 V6 有了质的飞跃。通过大幅改善动机与旋律质量,现在用户可以制作出质感更为细腻的个人独家 BGM,音质已经达到专业级水准。与此带来的就是人声与乐器真实度进一步增强,做出来的每一首歌都很好听。
而且,生成的歌曲对于音乐从业者也更具启发。
我们都知道,传统的自回归(Autoregressive, AR)模型虽然已经具备较强的音频保真能力,但其基于逐 token 预测的范式,本质上并不符合人类在音乐创作中「先规划整体,再填充细节」的思维过程。这种不匹配往往导致生成音乐缺乏连贯的结构性与艺术性。
在这次 V7 版本中,Mureka 对 MusiCoT(专为音乐生成而设计的链式思维提示方法)技术做了重大升级。听起来有点复杂,但核心目标其实很简单:让 AI 写歌更像人,更有章法、更好听。
其实,这次版本的创新性,可以分三点来说:
1、先写大纲,再写旋律,就像人类作曲那样
以往的 AI 作曲,容易顾头不顾尾,比如前半段情绪很激烈,后半段却突然变成轻快,听起来就不自然。而 MusiCoT 会让模型先规划整首歌的结构:要分几段?情绪怎么走?用什么乐器?就像人写歌前先打个草稿,后续的旋律才更连贯、有起伏。
2、AI 的创作过程变得“看得懂”,还能模仿风格但不抄袭
Mureka 引入了一个叫 CLAP 的技术,让 AI 的音乐创作思路可分析、有迹可循,不像以前那样“黑箱”。比如你给它一段你喜欢的音乐作为参考,它不会照搬复制,而是提取其中的风格、节奏感,用自己的方式创作出类似的风格,适合变奏、混音等玩法。
3、主观听起来更舒服,客观评分也更高
Mureka做了大量对比实验,结果很明确:用上 MusiCoT 的 AI 音乐作品在旋律连贯性、结构完整性、听感自然度等方面,全面胜出。无论你是音乐人还是普通听众,都能感受到音乐质量的提升。
所以,得益于 MusiCoT 的升级和应用,部分生成作品能够做到为音乐人提供更多创作灵感。
其实,在体验过程中,我非常喜欢的一个功能就是自定义音色功能,这是 Mureka 非常具有颠覆性的一个功能——全球首个支持自定义音色的AI音乐生成平台。我们用户不仅可以选择预设的歌手音色,甚至可以上传自己的声音,让 AI 用你的声音来演唱创作的歌曲。想象一下,你可以让 AI 帮你出一张完全属于自己声音的专辑!
这是其他 AI 音乐平台不具备的功能。
整体的使用方式也非常简单,要不我说国产产品人性化呢?产品的布局以及整个操作步骤写的很清晰,普通小白也能轻松上手。
大家可以听一听我制作的音乐,真的非常好听,听听最新 V7 模型的歌唱质感。
除了音乐模型有了重大升级之外,还有一个是我们做短视频或者自媒体人非常喜欢的功能,就是音频模型:Mureka TTS V1。这个功能在国内即将上线,大家可以期待一下。
Mureka TTS V1 支持 Voice Design 能力,用户可以通过自定义文本输入想要的语音特征获得对应的音色。
不论是真实人物、虚拟人物还是配音角色都能搞通过文本来控制,摆脱了过去只能通过现有音色库实现音色克隆,只能使用已经存在的音色形式。
简单来讲,即将全新上线的 Text-To-Speech 功能,用户可以完全通过文本来控制音色生成。这意味着你可以用文字描述你想要的声音特质,比如"温柔的女声"、"磁性的男声"等,AI 会根据描述生成对应的音色效果。
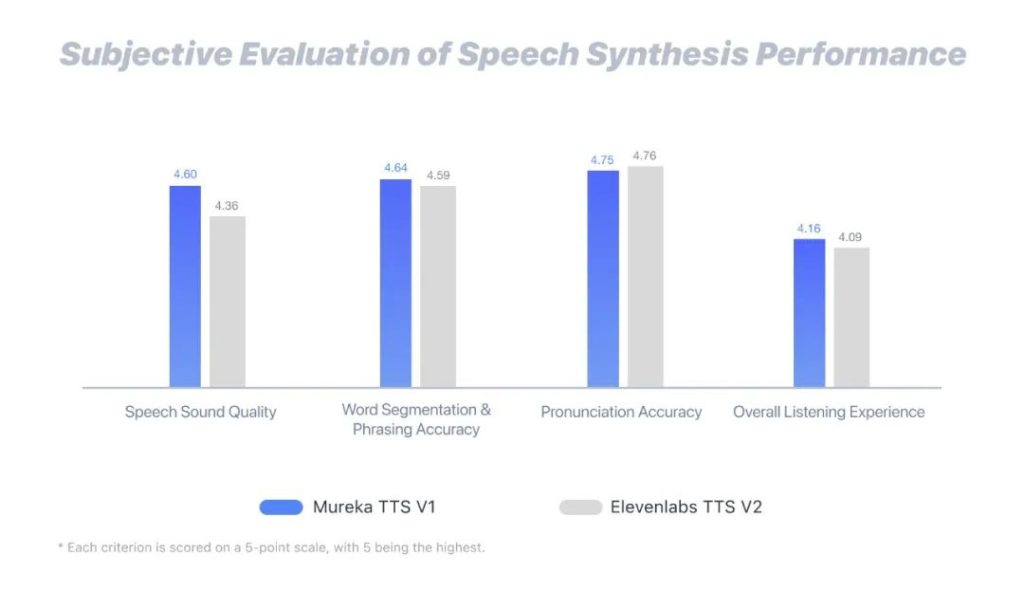
根据语音合成性能的评测显示, Mureka TTS V1 在大多数指标上都与行业领先的 Elevenlabs TTS V2 不相上下,甚至在语音音质、分词断句和整体听感方面都略有优势。
所以,你看,从 V7 音质的大幅提升,到自定义音色功能,再到全新的 Text-To-Speech 功能,还有之前的智能音乐参考系统,结合它又是全球首个开放 API服务的 AI 音乐生成平台。我说 Mureka 不仅仅是一个简单的音乐生成工具,而是一个完整的音乐创作生态系统。是不是一点也不假?
更重要的是:这是国产自研,数据可控、生态本地化,更贴近咱们中国音乐人的使用习惯。
目前,Mureka 提供网页版和 App,完全零门槛使用,无论你是音乐小白,还是内容创作者,都能快速搞定一首完整作品。
最后,我想说,AI 是一种平权工具,它赋予了我们普通人更多的能力。Mureka 让音乐,不再是“专业人士”的专属领域。
Mureka 代表的,不只是一个新工具,更是创作范式的改变。
它让我们看到,音乐不一定从五线谱开始,而可以从一句灵感、一段文字开始——AI 会把后面的一切都做完。而这,才是 AI 创意工具最有价值的地方:让更多人可以自由创作,而不是更少。
现在,是你该试一试 AI 帮你唱出灵魂的时候了。
上一篇接下来,大量的面试中,将会出现 Vibe Coding 测试下一篇不会写代码也能做出专业网页,扣子空间把程序员都干懵了
个人观点,仅供参考